怎么加杠杆资金炒股 NVIDIA、AMD旗舰显卡挑战DeepSeek R1模型:谁才是适配LLM PC性能的高手
发布日期:2025-02-21 22:23 点击次数:70
国产大语言模型DeepSeek现在的热度可以说是非常高怎么加杠杆资金炒股,它还引发了业界对AI大模型应用的更多畅想,今年1月发布了DeepSeek-R1人工智能大型语言模型,适用于数学、编码和逻辑等任务,性能对标OpenAI o1,随后在全球范围内掀起了一股热潮,成为了行业的焦点。

目前深度求索(DeepSeek)线上提供服务的模型主要是DeepSeek V3和DeepSeek R1,它们都是开源的,可以在huggingface以及它在国内的镜像站上下载。这些模型都可以通过各种AI平台,如Ollama、Jan.AI、LM Studio和AnythingLLM等轻松地在Windows平台上运行,而这些平台使用的底层核心库是流行的开源C++库llama.cpp。

至于DeepSeek V3和DeepSeek R1两种模型的区别,大家请看以下DeepSeek R1的自己的回答:
1.模型定位
DeepSeek V3:作为通用型智能助手,更注重广泛场景的适应能力,例如知识问答、多轮对话、文本生成等通用任务。
DeepSeek R1:属于优化迭代版本,可能在响应效率、特定任务(如代码生成、数据分析)或垂直领域(如金融、客服)的针对性表现上进行了增强。
2.功能侧重
V3 强调平衡性,适合日常交互和多样化需求。
R1 可能针对实时性、复杂任务处理或行业需求进行了专项优化(具体需参考官方说明)。
3.技术迭代
R1作为后续版本,可能基于V3的反馈数据进行了模型调整,例如优化推理速度、降低资源消耗或提升特定场景的准确性。
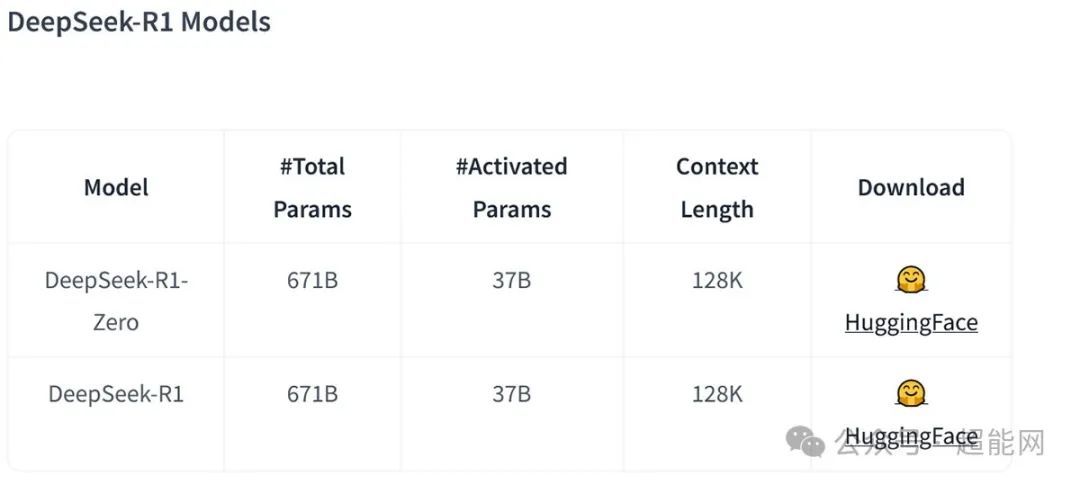
DeepSeek的模型都是开源的,所以理论上都可以下载下来自己搭起来跑,但是嘛,DeepSeek V3只有满血版的671B可供下载,DeepSeek R1满血版也是671B,这模型压根就不是给个人用户玩的,得用服务器来跑。
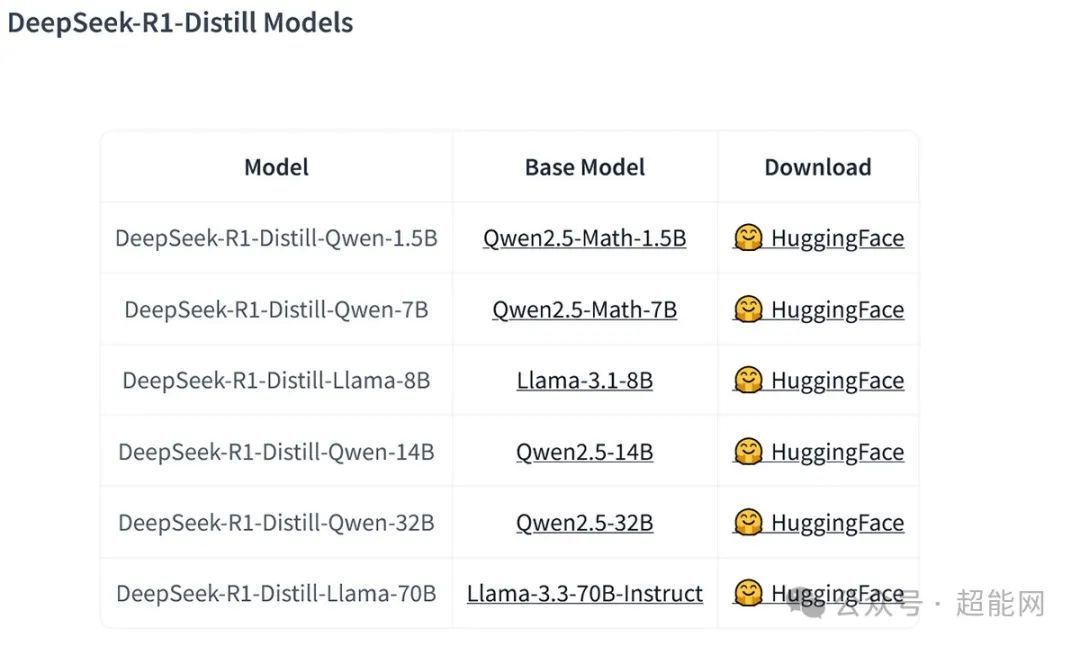
但DeepSeek R1有各种蒸馏小模型可供下载,它们是基于开源模型使用DeepSeek R1进行微调,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果,自用的话这些模型更加合适。
使用较为常见的int4量化模型的话,8B以下的用最为常见8GB显存显卡就能跑了;14B模型的大小是9GB;所以得用10GB显存的显卡,32B模型大小是20GB,需要24GB显存的显卡;70B模型的大小是43GB,这已经不是单张消费级显卡能跑的东西了,需要那些48GB显存的专业卡,用普通显卡的话至少得上双卡。
而llama.cpp开源库里面包含一个基准测试工具llama-bench,可用来测试各种硬件上的LLM推理性能,接下来我们就要用它来跑跑NVIDIA和AMD两家的旗舰显卡运行DeepSeek R1蒸馏模型的速度如何。
测试平台与说明

本次测试跑了DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B和DeepSeek-R1-Distill-Qwen-32B这三个模型,测试平台使用酷睿i9-14900K搭配微星Z790 CARBON WIFI II主板,考虑到32B模型可能会占用大量内存,所以用了DDR5-6400 32GB*2套装。

测试使用的显卡包括RTX 5090、RTX 5090 D、RTX 4090、RTX 4090 D以及AMD的RX 7900 XTX,这些NVIDIA显卡全部都使用CUDA来运行,而RX 7900 XTX则会测试使用Vulkan和ROCm时的情况。
DeepSeek R1推理测试
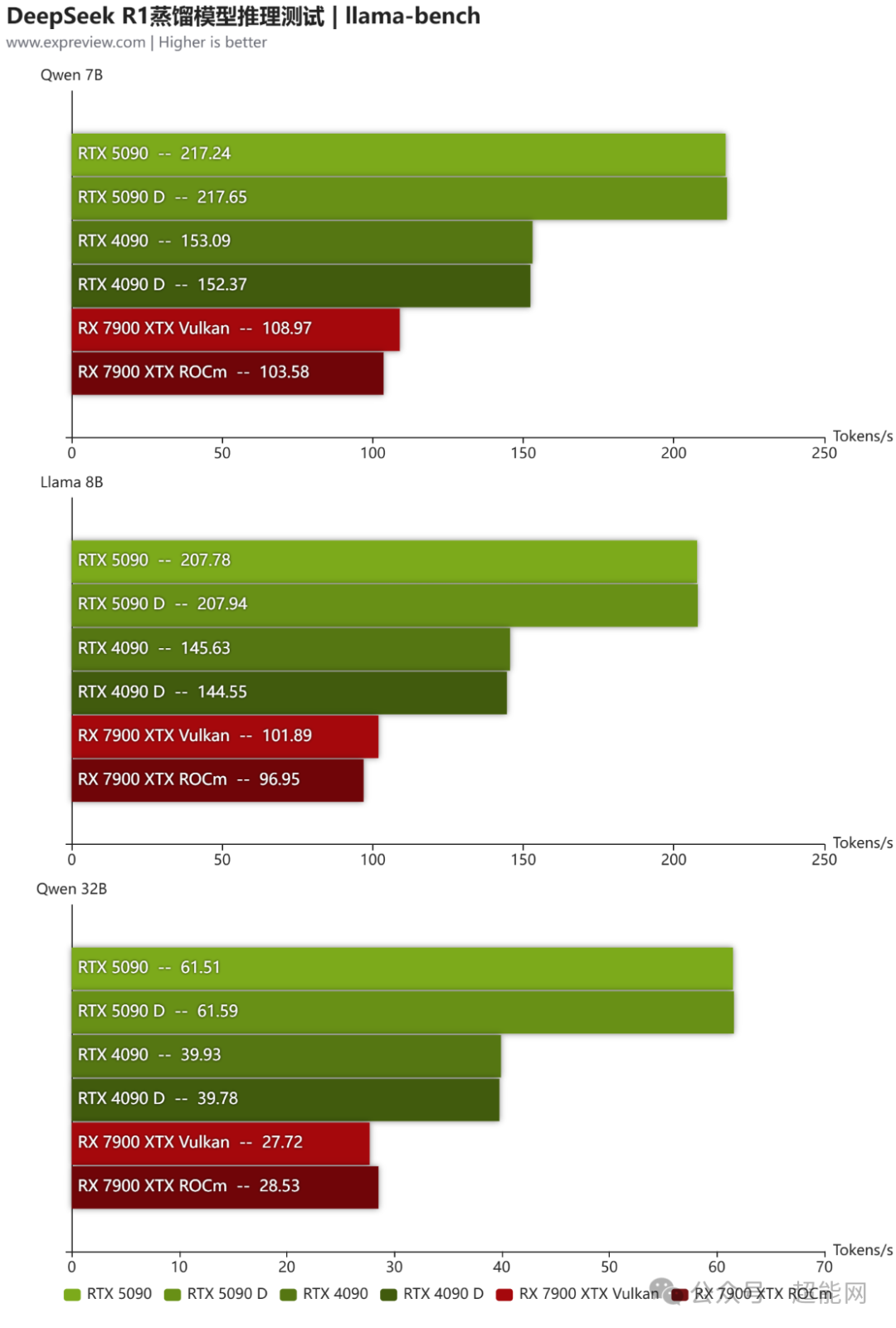
可能在纯CUDA环境下大语言模型推理是吃不满RTX 5090和RTX 4090的算力的,导致测试出来它们和RTX 5090 D和RTX 4090 D一点差距都没有,如果能跑TensorRT就可能有区别,当然也有可能是瓶颈是显存带宽。RX 7900XTX在跑7B和8B模型时使用Vulkan是比ROCm更快的,但跑32B模型时就是ROCm更快。
在运行小型DeepSeek蒸馏模型的时候,RTX 5090 D的每秒输出Tokens比上代RTX 4090 D速度快40%以上,如果是较大的DeepSeek-R1-Distill-Qwen-32B模型的话速度会快55%之多。对比RX 7900XTX,RTX 4090 D要比它快40%以上,而最新的RTX 5090 D甚至是它的两倍之多。
造成这原因,GPU核心算力是一个因素,RTX 5090 D的算力在这三张卡里面最强这点毋庸置疑,而RTX 4090 D本身算力也要比RX 7900XTX高一大截,但从RTX 5090与RTX 5090 D、RTX 4090与RTX 4090 D性能没差距来看,使用CUDA去推理其实没有完全发挥出GPU的AI算力。
另外一个关键因素是显存的带宽,在这三张显卡里面RX 7900XTX的显存带宽是最低的,只有960Gbps,而RTX 4090 D的显存位宽和RX 7900XTX同是384bit,但使用了速度更快的GDDR6X显存,所以带宽更高有1053Gbps,而RTX 5090 D更是配备了512bit的GDDR7显存,带宽高达1792Gbps,跑LLM推理是非常吃显存带宽的,RTX 5090 D能比RTX 4090 D快这么多的原因很大一部分就是带宽的关系。
至于是否采用PCIe 5.0接口,这并不是单卡推理负载的瓶颈,在加载模型时确实与接口带宽有些关系,但此时瓶颈通常是在你的SSD上而不是显卡这边。
全文总结
个人想本地部署DeepSeek R1 671B模型基本是不用想的,这种基本上只能在服务器上面跑,但在本地跑小型化后的蒸馏模型是没问题的,DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Llama-8B这两个体积较小的适合显存只有8GB的显卡部署,而且由于比较小的关系所以跑起来速度也很快,然而也是由于较小的关系它们也只是属于能用的范畴,而使用12GB显存显卡的朋友可以跑DeepSeek-R1-Distill-Qwen-14B这个模型,对于LLM来说通常是参数越多给出的答案越精确越全面。

想要真正好用的还得DeepSeek-R1-Distill-Qwen-32B这种有320亿参数的模型,当然这就得上比较高级的显卡了,最好的选择自然是最新的RTX 5090 D,输出tokens/s非常的高,而上代旗舰RTX 4090 D的速度其实也不差,表现均优于AMD的RX 7900 XTX,这自然和NVIDIA GPU本身算力更强的有关,RTX 4090 D本身的AI算力就比RX 7900 XTX高得多,而RTX 5090 D的显存带宽比它们俩高得多,自然性能也更好。
不同大小的DeepSeek R1蒸馏模型的显卡推荐表如下:

而且NVIDIA的软件适配性比AMD的更好怎么加杠杆资金炒股,目前支持CUDA的软件非常多,这次跑的llama.cpp运行的也是CUDA,AMD这些年来也在推自己的ROCm,我们这次也跑了,但用ROCm的表现并不一定比通用API Vulkan更好,这就挺尴尬的,AMD在软件方面的支持确实没NVIDIA好,而且NVIDIA对于AI内容有性能更好的TensorRT,日后这些AI软件能升级支持TensorRT的话定能发挥出更好的性能。